Description
Code Sample, a copy-pastable example if possible
def _read_header(self):
# ...
# remove format details from %td
self.fmtlist = ["%td" if x.startswith("%td") else x
for x in self.fmtlist]which allows for this check to succeed when format details are present
def _stata_elapsed_date_to_datetime_vec(dates, fmt):
# ...
elif fmt in ["%td", "td", "%d", "d"]: # Delta days relative to base
# ...Problem description
It looks like pandas is attempting to the right thing by dropping format codes from %td formats so that they will match the correct format in _stata_elapsed_date_to_datetime_vec
I handle a large number of Stata files and arbitrarily supporting display formats with only %td is problematic.
Expected Output
Ideally none of these four assert statements would fail
import datetime as dt
import pandas
# File attached below
d1, d2, d3, d4 = pandas.read_stata('STATA_DATES.DTA').iloc[0]
expected = dt.datetime(2006, 11, 21)
assert d1 == expected # fails - format is %dD_m_Y
assert d2 == expected # succeeds - format is %tdD_m_Y
assert d3 == expected # fails - format is %tcD_m_Y
assert d4 == expected # succeeds - format is %tcProposed Fixes
-
Strip formats from other types by adding extra list comprehensions in
_read_header. My current workaround is to subclassStataReaderand add this logic after_read_header. -
Use
str.startswith's lesser-known tuple argument
In_stata_elapsed_date_to_datetime_vecchange lines like
elif fmt in ["%td", "td", "%d", "d"]: # Delta days relative to base
to
elif fmt.startswith(("%td", "td", "%d", "d")): # Delta days relative to base
this obviates the need for the list comprehensions in the first place.
Output of pd.show_versions()
INSTALLED VERSIONS
commit: None
python: 3.6.1.final.0
python-bits: 64
OS: Darwin
OS-release: 16.6.0
machine: x86_64
processor: i386
byteorder: little
LC_ALL: None
LANG: en_US.UTF-8
LOCALE: en_US.UTF-8
pandas: 0.19.2
nose: None
pip: 9.0.1
setuptools: 27.2.0
Cython: None
numpy: 1.12.1
scipy: None
statsmodels: None
xarray: None
IPython: None
sphinx: None
patsy: None
dateutil: 2.6.0
pytz: 2017.2
blosc: None
bottleneck: None
tables: None
numexpr: None
matplotlib: None
openpyxl: None
xlrd: 1.0.0
xlwt: None
xlsxwriter: None
lxml: None
bs4: None
html5lib: None
httplib2: None
apiclient: None
sqlalchemy: None
pymysql: None
psycopg2: None
jinja2: None
boto: None
pandas_datareader: None
Sample Files
STATA_DATES.DTA.zip the DTA file used for the Expected Output. It's a single row with 4 values
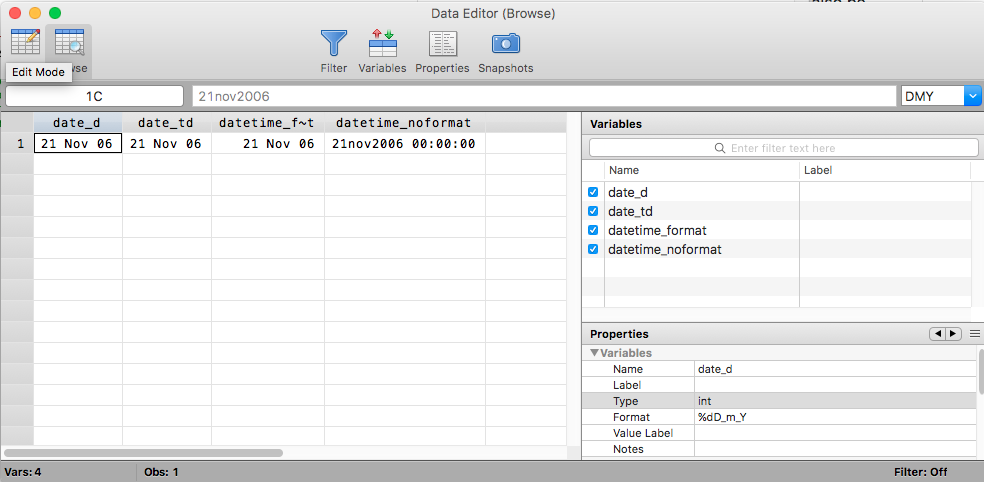
The file was generated from this CSV file with the following commands.
stata_dates.csv.zip
load ~/tmp/stata_dates.csv
format date_d %dD_m_Y
format date_td %tdD_m_Y
format datetime_format %tcD_m_Y
format datetime_noformat %tc
save ~/tmp/STATA_DATE_D_TD.DTA